

SVILUPPARE UNA TECNOLOGIA OCR AFFIDABILE PER LETTURE DIGITALI.
- On 9 Dicembre, 2019
- .net, cifre digitali, intelligenza artificiale, lettura contatori, ocr, optical recognition
L’automazione prende sempre più piede all’interno delle aziende, anche quelle non necessariamente tecnologiche.
L’attuale periodo storico si contraddistingue soprattutto dall’applicazione sempre più vasta dI reti di elaboratori che, non avvertendo la fatica, possono svolgere con ripetitività e velocità compiti che talvolta possono essere faticosi e/o monotoni seguendo un procedimento rigoroso e ben definito che prende il nome di algoritmo.
Questo sforzo di perfezionamento degli algoritmi ha portato nel tempo a definire tecnologie evolute quali l’intelligenza artificiale, il pattern Recognition e il Machine Learning, per citarne alcune.
Una dei processi che si è cercato di automatizzare e che è ancora in fase di ottimizzazione è stato l’estrapolazione di lettere e/o numeri da un’immagine ed è proprio su questo che ci soffermeremo, sul sistema di riconoscimento ottico dei caratteri detto anche OCR (Optical Character Recognition).

L’OCR è un vero e proprio campo dell’intelligenza artificiale che ancora oggi presenta delle lacune che incidono negativamente sulla sua efficienza. Sono numerose le volte in cui un sistema OCR non riesce ad interpretare correttamente i caratteri ed effettua, di conseguenza, letture errate. Gli OCR risultano essere ancora poco affidabili.
Una delle esigenze che può presentarsi in un’azienda è la lettura automatica di un valore numerico che rappresenta la misurazione del consumo di un qualcosa che nel nostro esempio possono essere gas, olio o energia elettrica da un contatore. Per poterla effettuare, è necessario avere un’immagine ben definita del valore posto su di esso e questa può essere facilmente ottenibile grazie all’uso di un’ip camera ben fissatagli davanti.
Le immagini catturate da una camera differiscono molto dai documenti scansionati o dai PDF. Loro spesso sono caratterizzate da vari difetti come la distorsione, il rumore, luce fioca o troppo forte, particolare font dei caratteri ecc … Estrapolare del testo o un numero da un’immagine e decifrare ogni singola lettera/cifra che lo compone è complicato, così come lo è garantire una lettura perfettamente riuscita, ma questo non significa che quest’ultima non possa essere effettuata o che aumentare l’affidabilità del sistema che la esegue sia impossibile. La nostra soluzione si basa su questo principio.
ANALISI DEL VALORE NUMERICO: IL CASO DELLA LETTURA DI UN CONTATORE DIGITALE
Nel nostro caso di studio, sviluppato per una commessa reale di un cliente, abbiamo realizzato un algoritmo proprietario e una applicazione .NET che leggesse le cifre dagli schermi di alcuni contatori digitali. A tale scopo sono state orientate verso il display del contatore delle videocamere IP e le relative immagini sono state catturate dall’applicazione ogni tot-secondi.
Abbiamo provato ad utilizzare le principali librerie o servizi di riconoscimento immagini e, con nostra grande sorpresa, abbiamo realizzato che l’indice di affidabilità del riconoscimento del nostro numero di 7 cifre era piuttosto aleatoria e gli strumenti comunemente disponibili per autocorrezione e filtraggio dei risultati sono ancora piuttosto limitati, se non inesistenti.
In ogni caso, approfondendo la vasta documentazione presente in rete sull’argomento, abbiamo acquisito alcuni capisaldi nel nostro ragionamento:
- i sistemi OCR sono complessi e imprevedibili e vanno misurati empiricamente
«Unlike a word processor or spreadsheet program, the behavior of an OCR system is complex and unpredictable. Like other pattern recognition systems, an OCR system is ” trained” using a set of data. Its performance when processing other data is not known a priori, and must be measured empirically». Stephen V. Rice, Measuring the accuracy of page-reading systems, Las Vegas: University of Nevada. Department of Computer Science, 1996.
- l’affidabilità delle letture OCR può essere migliorata con un adeguato supporto statistico
- la precisione del risultato aumenta introducendo delle soglie di filtraggio
- è necessario introdurre nelle applicazioni quotidiane degli automatismi per l’individuazione e segnalazione di errori
Entriamo nel dettaglio della nostra esperienza:
Il valore numerico presente sul contatore è inizialmente composto da una singola cifra (la cifra 0), durante l’incremento, il numero di cifre da cui è costituito tende ad aumentare.
Ogni cifra può essere associata ad una posizione (quella ricoperta all’interno dell’intero valore numerico).

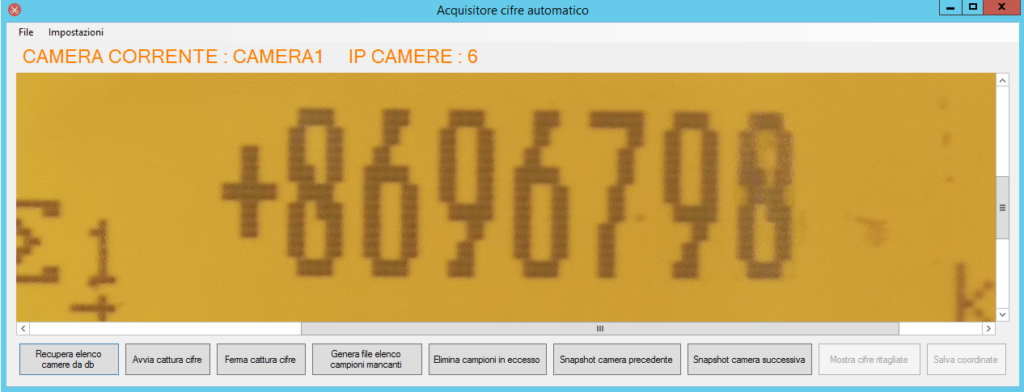
Prendiamo come esempio il contatore in figura. Il valore numerico presente su di esso (quello dove ogni cifra è stata racchiusa all’interno di un rettangolo blu), è composto da 7 cifre e un simbolo anteposto prima di esse (il “+”). Considerando anche il “+” come una cifra, possiamo dire che la lunghezza complessiva del valore numerico è pari ad 8. Ogni cifra occupa una posizione. L’ultima cifra (7) occupa la posizione numero 8, la penultima cifra (0) la posizione 7, la terzultima (5) la posizione 6 e così via, fino a raggiungere la posizione 1 che è occupata dal simbolo “+”.
Durante la fase di incremento, il simbolo “+” è l’unico elemento che scala di posizione. Supponiamo per un attimo che il valore numerico sia costituito da 4 cifre (3 cifre sommate alla presenza del simbolo “+”) e che tale valore sia il seguente : +796. Definiamo le posizioni partendo dall’ultima cifra. Poiché la lunghezza massima di cifre che il valore numerico può raggiungere in questo contatore non supera le 8 (tenendo conto sempre del simbolo “+”) ed è quindi fissa, definiamo le posizioni partendo sempre dall’ottava. L’ultima cifra (6) occuperà l’ottava posizione, la penultima cifra (9) occuperà la settima posizione, la terzultima cifra (7) la sesta posizione e la quartultima cifra (il simbolo “+”) occuperà la quinta posizione. Il simbolo “+” è collocato quindi alla posizione 5. Non appena il valore numerico sarà composto da quattro cifre (oltre al simbolo “+”), il simbolo “+” occuperà la quarta posizione (quindi scalerà di posto) e così via.
Possiamo anche dire che durante l’incremento, se il numero di cifre presenti in un determinato momento sarà minore della lunghezza massima che il valore numerico può raggiungere, ci saranno delle posizioni vuote (dove non comparirà nessuna cifra/simbolo ma sarà presente solo e soltanto lo sfondo arancione). L’ottava posizione, invece sarà sempre popolata perché inizialmente il contatore è inizializzato a 0 e non ci sarà mai uno spazio vuoto, così come non ci sarà mai il simbolo “+”.
Possiamo quindi stilare una casistica.
Per ogni posizione, durante la fase di incremento, si presenterà un determinato range di elementi definiti qui di seguito :
posizione 8 → compariranno solo le cifre da 0 a 9;
posizioni 7, 6, 5, 4, 3, 2 → compariranno le cifre da 0 a 9, il simbolo “+” e lo spazio vuoto;
posizione 1 → compariranno il simbolo “+” e lo spazio vuoto.
Per poter leggere il valore numerico, l’algoritmo deve essere in grado di associare tutti gli elementi che possono comparire per ogni posizione a ciò che effettivamente contengono (cifra, spazio vuoto, simbolo). Tutti gli elementi che possono comparire per ogni posizione, per semplicità, da adesso in poi verranno chiamati “campioni”. Per fare quanto detto poc’anzi, i campioni per ogni posizione vanno raccolti e salvati all’interno di una struttura di cartelle ben definita e rinominati (da un operatore) secondo ciò che rappresentano.
Noi abbiamo optato per la seguente struttura :
L’immagine che rappresenterà lo spazio vuoto sarà rinominata come “null”, quella che rappresenta il simbolo “+”, invece, “+”. Tutte le immagini che contengono una cifra, saranno rinominate esattamente con il nome della cifra stessa presente su di esse.
Chiunque stia leggendo quest’articolo starà sicuramente chiedendosi il motivo per cui si sta strutturando il dataset in questo modo, il perché della storicizzazione di tutti i campioni per ogni posizione che possono sembrare anche ridondanti dato che ogni elemento che può comparire all’interno del valore numerico potrebbe essere recuperato (in teoria) solo una volta. Tutto questo è strettamente correlato all’algoritmo di similarità (che tratteremo più avanti) che verrà utilizzato per risalire alle cifre presenti nell’istantanea.
Il prelevamento dei campioni risulterà essere abbastanza lento perché bisognerà attendere che essi compaiano all’interno del valore numerico, però, quest’operazione, una volta compiuta, aumenterà esponenzialmente l’affidabilità del sistema di lettura automatica ed è proprio questo l’obbiettivo.
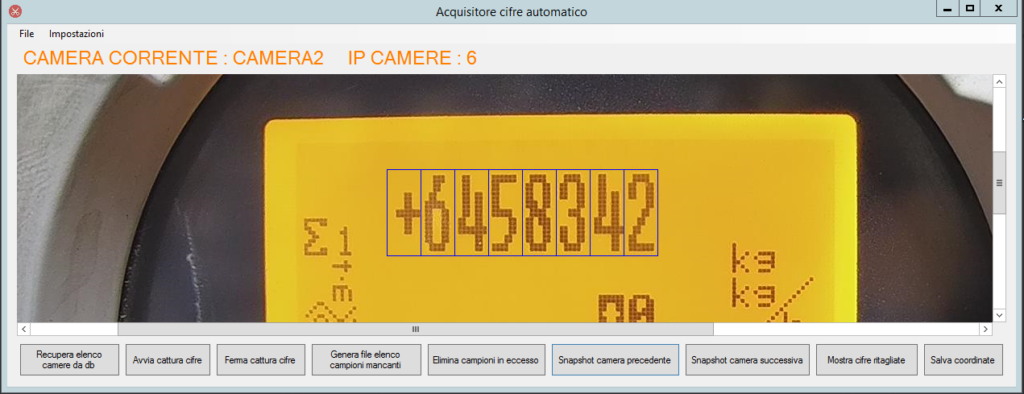
E’ impensabile, però, effettuare la raccolta dei campioni per ogni posizione manualmente. La nostra idea è stata quella di progettare e realizzare un programma che lo facesse al posto nostro, che ci permettesse in qualche modo di definire le coordinate dei rettangoli blu demarcanti le varie cifre mediante una selezione ed usare quest’ultime per ritagliarli e salvarli in maniera del tutto automatica.
Per una questione di velocità abbiamo fatto in modo che la selezione venisse effettuata solo su una cifra (l’ultima) e che le coordinate degli altri rettangoli contenenti tutte le altre cifre venissero calcolate automaticamente.
https://www.tpsoluzioni.it/wp-content/uploads/2019/11/AcquisitoreCifre.mp4
L’applicativo consente di recuperare tutte le IP camere presenti nel database (dopo essere state aggiunte mediante un’applicazione che è dedita alla fase di setup di quest’ultime), di avere un’anteprima delle cifre ritagliate dopo aver effettuato la selezione , di avviare e arrestare la procedura di ritaglio automatico in qualsiasi momento, di generare un file con estensione “txt” contenente la panoramica della raccolta formatasi fino al momento corrente e di eliminare i campioni in eccesso (quelli ridondanti) nel momento in cui ce ne siano.
L’inserimento delle ip camere avviene mediante il seguente applicativo :
Visto il funzionamento della collezione delle immagini, possiamo ora iniziare a cimentarci sulla lettura vera e propria ed introdurre l’algoritmo di similarità che viene utilizzato per effettuarla.
Supponiamo di effettuare uno snapshot in tempo reale del contatore e di ottenere il seguente valore numerico : +9335704 (come riportato nell’immagine che segue).

L’algoritmo di lettura si baserà su un confronto tra i ritagli delle cifre di cui è composto l’intero valore e tutti gli elementi che possono comparire nella la posizione che ognuna di esse occupa (che sono stati storicizzati dal programma di acquisizione automatico).
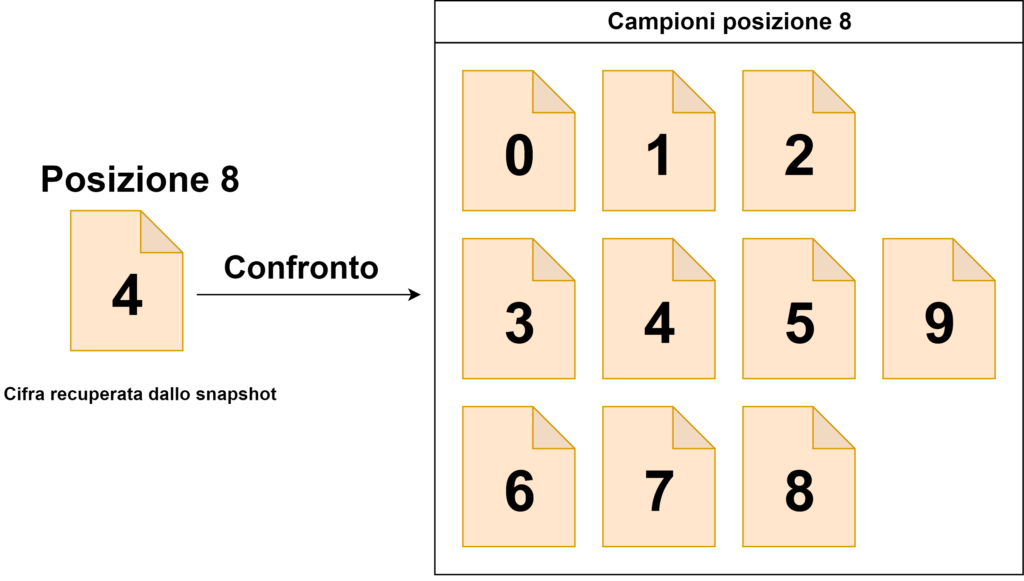
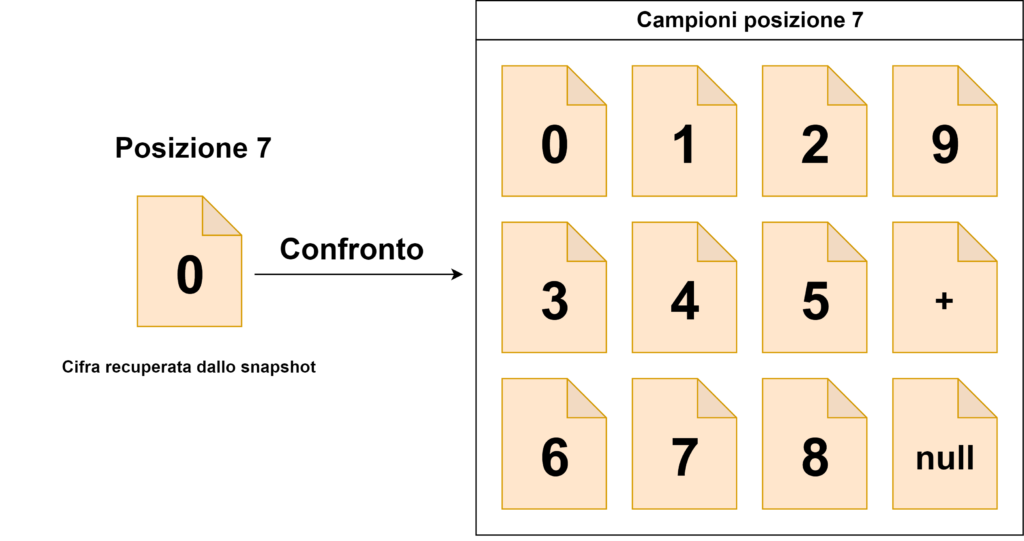
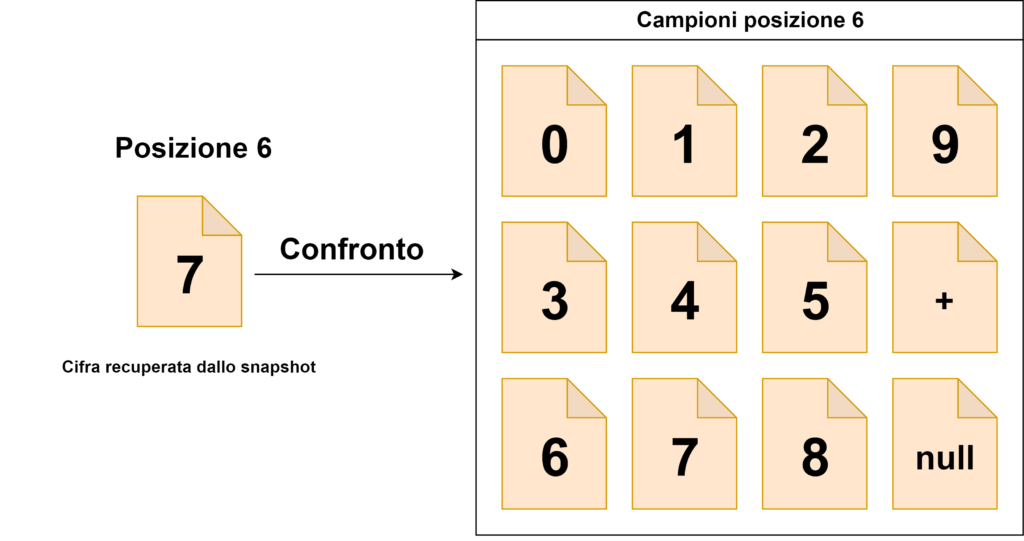
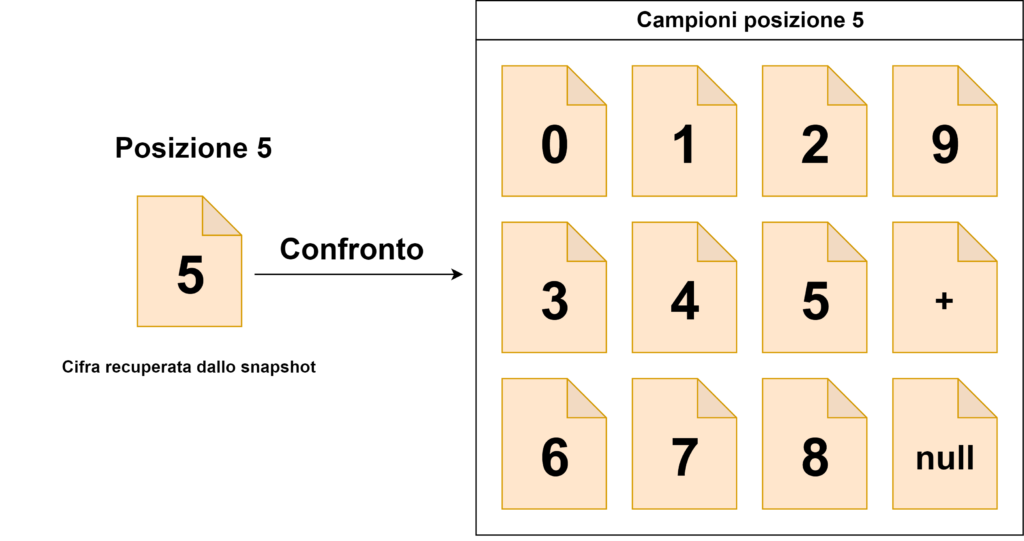
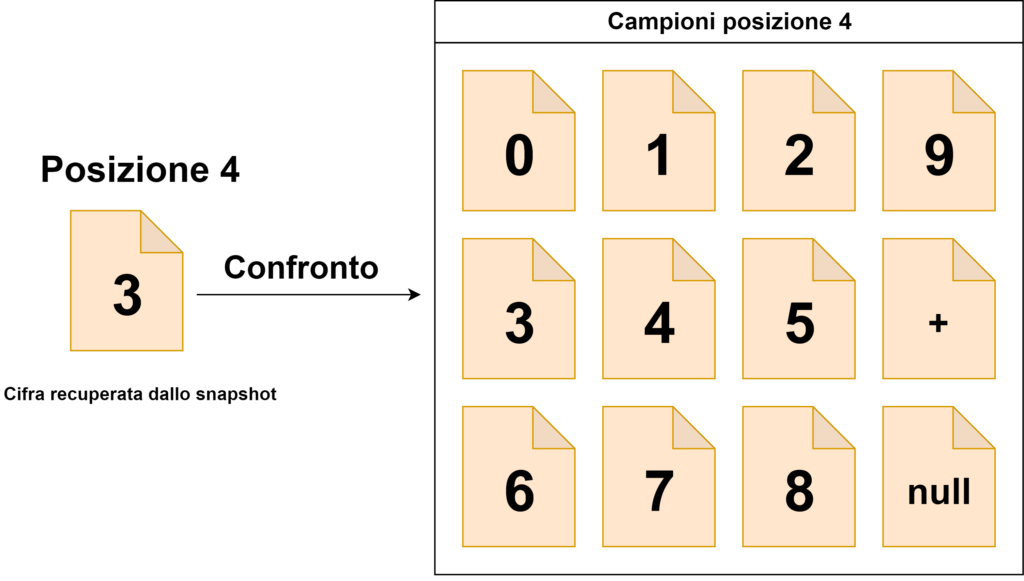
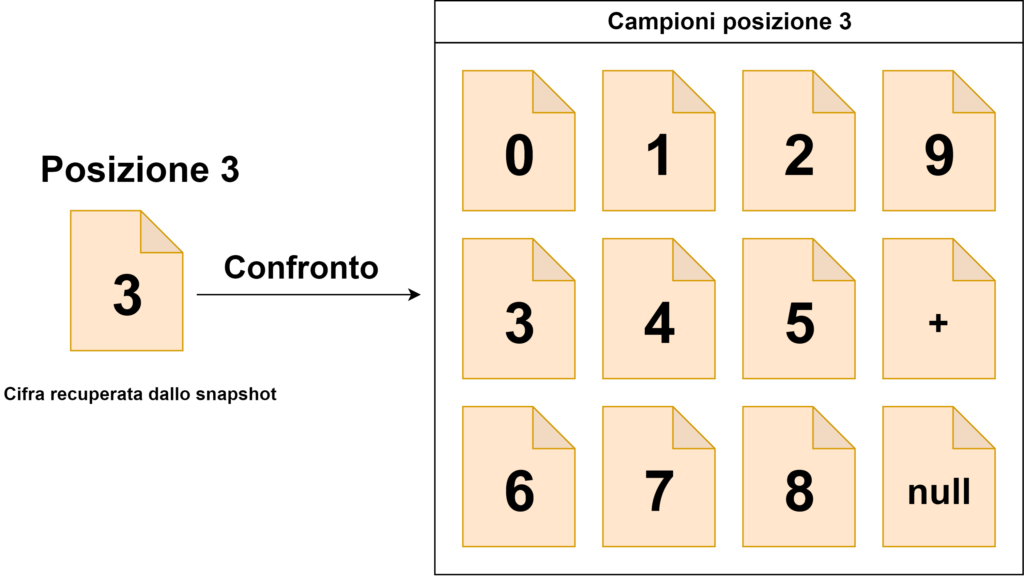
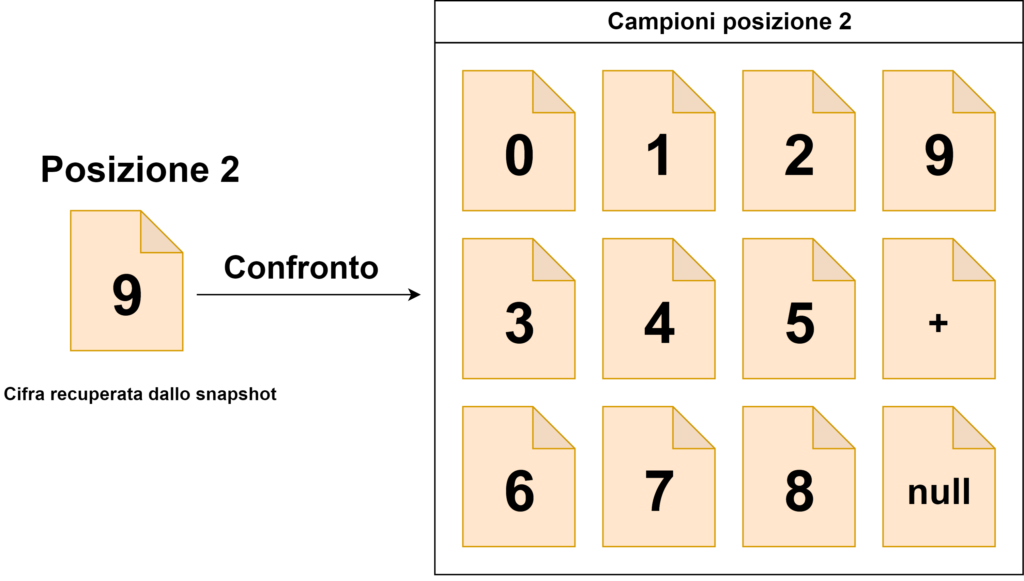
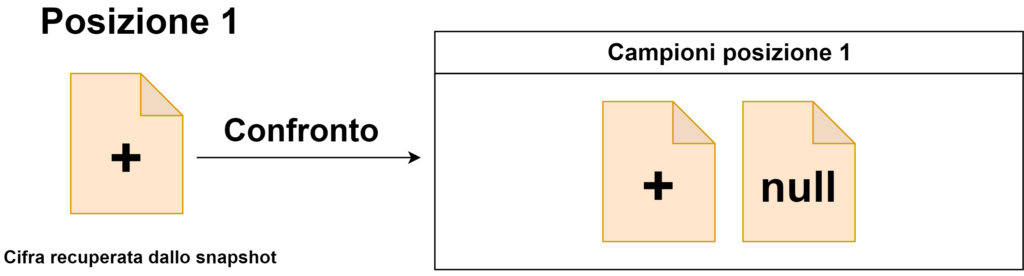
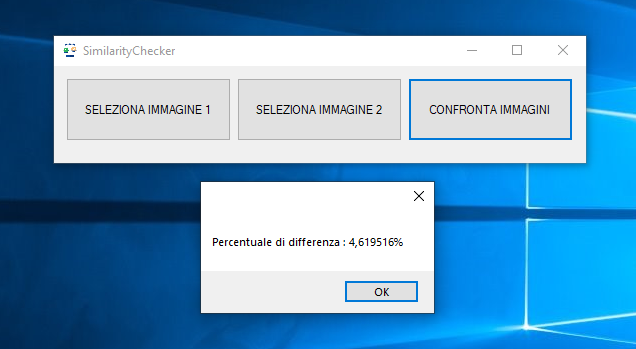
La cifra letta sarà uguale al nome con cui è stata rinominato il campione che risulta essere più simile a quello ritagliato dallo snapshot ottenuto dalla camera (quindi, in sostanza, prenderemo come valido il nome dell’immagine campione che ha la differenza in termini di percentuale minore). Il valore letto sarà uguale alla concatenazione di tutte le cifre.
La domanda è : perché i campioni vengono prelevati per ogni posizione? Non basta prenderli una volta da qualsiasi posizione? La risposta è no. I test effettuati ci hanno dimostrato che l’algoritmo di lettura fallisce quasi sempre a causa della distorsione delle cifre presenti sulle immagini.
Adottando questa soluzione, l’affidabilità della lettura aumenta esponenzialmente.
Una serie di test effettuata su circa 3.000 immagini riferite alla singola camera ha delineato un’attendibilità pari al 100% anche se sull’immagine istantanea analizzata sono presenti cifre in fase di cambiamento avanzato (esempio : un 2 che è sul punto di diventare 3).
Per calcolare la percentuale di similarità tra due immagini, ci si può servire di diversi algoritmi e funzioni (non riporteremo quella utilizzata da noi per ragioni di riservatezza industriale)
ATTENZIONE!
L’algoritmo, con questa soluzione, leggerà sempre in maniera corretta a patto che siano utilizzati alcuni accorgimenti ambientali:
- La condizione di luce presente sullo snapshot effettuato sul momento non sia molto differente rispetto a quella che era presente nel momento in cui i campioni sono stati prelevati;
- L’ip camera che inquadra il contatore h24 non venga spostata, altrimenti bisognerà prelevare nuovamente tutti i campioni (a meno che non la si riposizioni esattamente nel punto in cui era prima dello spostamento, anche se la possibilità di riuscirsi è bassa);
- Non venga spostato il contatore;
- Non vengano posti eventuali oggetti davanti alla camera o al contatore;
- Non vi siano riflessi né sulla camera né sul contatore;
- Non vengano eliminati i campioni salvati.
I casi riportati, qualora dovessero verificarsi, disorienterebbero l’algoritmo di similarità provocando una lettura errata.
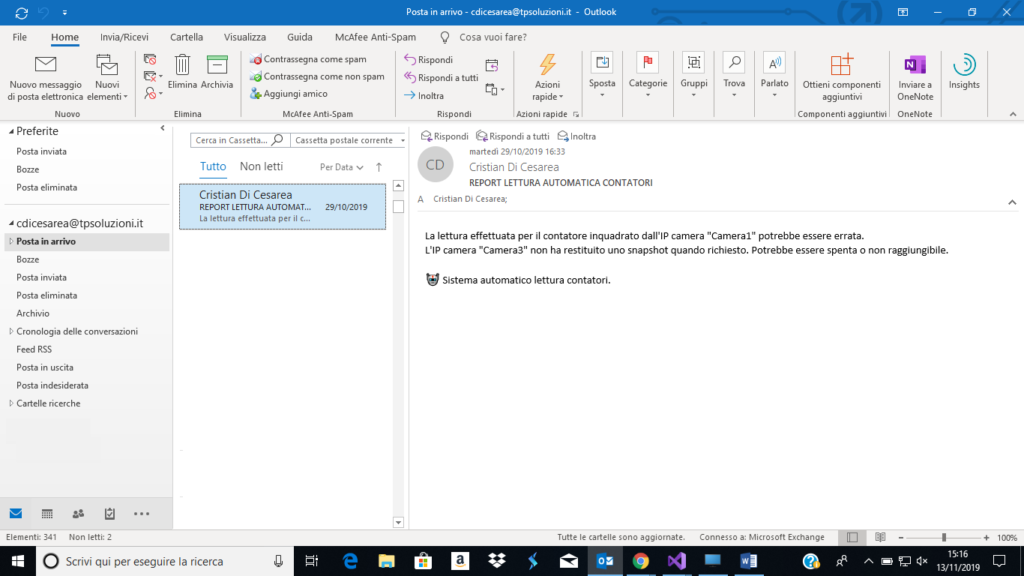
Un buon sistema, però, deve essere in grado di avvertire un operatore (magari inviando un’e-mail) nel momento in cui si verifichino una o più situazioni di questo genere. Esso deve essere in grado di segnalare anche un improvviso passaggio dallo stato online ad offline da parte di una o più ip camere.
Se un’ip camera è offline, non viene mostrata alcuna istantanea nel momento in cui viene richiesta e questo può essere gestito con facilità, cosa che non può essere ribadita per tutti gli altri casi.
L’algoritmo, per poter capire se la lettura effettuata sia completamente o parzialmente errata, deve saper distinguere quando l’immagine della cifra prelevata dallo snapshot non è simile a tutti i campioni prelevati per la posizione che essa occupa. Per fare questo, dovremmo essere a conoscenza di un una percentuale che avrebbe come scopo quello di delineare la soglia dopo cui sarebbe possibile affermare che un’immagine, confrontata con sé stessa, non è più simile (soglia di dissimilarità). Il valore che (in termini di percentuale) indica ciò, prende il nome di “tolleranza”.
La tolleranza si può ricavare salvando all’interno del database, per ogni lettura effettuata, la percentuale di differenza minore ottenuta dai confronti precedentemente effettuati con l’algoritmo di similarità per ogni posizione, per poi prendere quella maggiore tra le letture effettuate in modo corretto dopo averle sommato un valore arbitrario (che non sia grande). Una volta nota la tolleranza per ogni posizione (che non è la stessa per ogni posizione), è possibile specificare nell’algoritmo di lettura automatica (collocato all’interno di una console application schedulata ed eseguita ad intervalli di tempo regolari) che se la percentuale di differenza minore ottenuta per la posizione corrente in fase di lettura è maggiore o uguale della tolleranza stabilita per tale posizione, allora esiste una cospicua possibilità che la cifra letta sia stata letta in modo errato. L’algoritmo leggerà comunque qualcosa (il nome con cui è rinominato il campione che risulta essere più simile a quella presente nello snapshot) però sarà consapevole che tale cifra possa non corrispondere a quella reale e, pertanto, invierà un’e-mail di avvertimento.
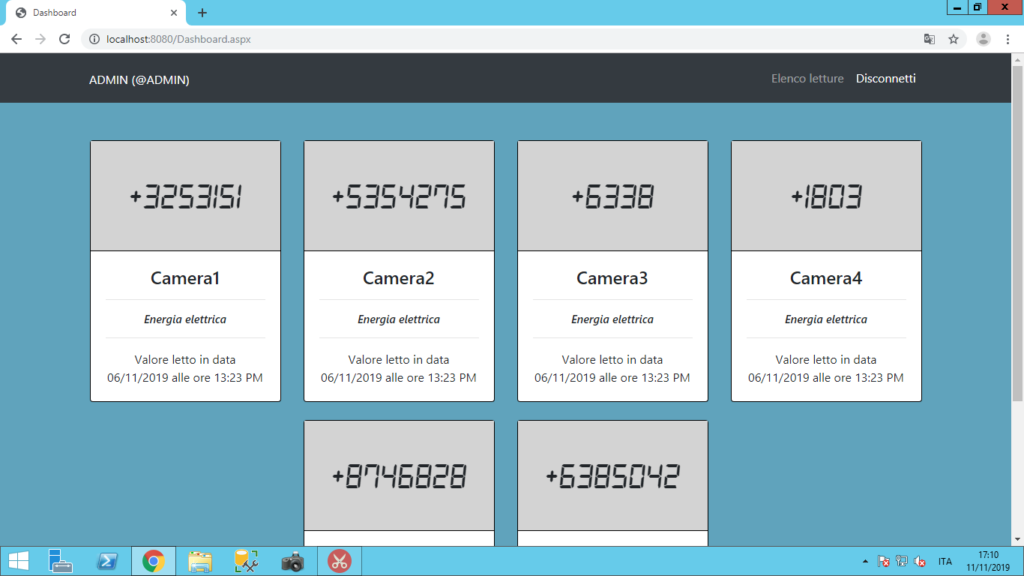
Una volta effettuate, le letture necessitano di essere visualizzate. A tale scopo abbiamo realizzato una web App dove vengono mostrate le ultime letture effettuate per ogni camera :
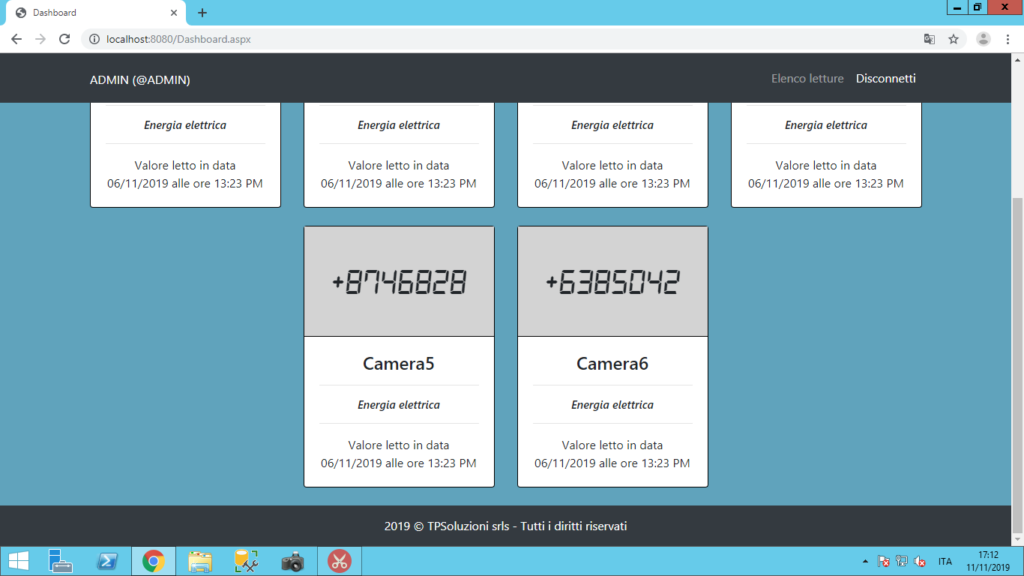
Per debug è stato davvero utile visualizzare (avendo anche la possibilità di applicare dei filtri di ricerca) le immagini da cui sono stati letti i valori per ogni camera.

Bene, se è nelle tue intenzioni realizzare un meccanismo di lettura automatica, puoi utilizzare alcuni di questi suggerimenti.
Qualora invece ti occorra la nostra esperienza al riguardo, non esitare a contattarci.
Buon divertimento! 👋😃

