
Manutenzione Indici in un database Microsoft SQL Server
- On 5 Settembre, 2019
- database, dba, dbadmin, index, microsoft dynamics, microsoft sql server, sql, sql server, sqlserver
COSA SONO GLI INDICI DI UN DATABASE
Un indice è una struttura dati ausiliaria che consente di recuperare più velocemente i dati di un database, evitando la lettura ripetuta dell’intero contenuto, tramite una selezione mirata.
L’idea su cui si basa la struttura di accesso degli indici ordinati è simile a quella che sta alla base dell’indice analitico di un libro di testo.
Gli indici vanno però usati consapevolmente, verificando quando sono effettivamente necessari e scegliendo con cura su quali campi della tabella applicarli. Abusare degli indici, potrebbe avere addirittura l’effetto di ridurre le performance I/O del database.
Quindi gli indici agevolano le operazioni di lettura, rendendo più onerose tutte le altre.
Gli indici vanno aggiornati ad ogni modifica apportata allo stesso database.
COME USARLI
Visto che, come in un libro, l’indice in se, deve essere un ponte, tra le informazioni che vogliamo recuperare dal database e la reale posizione dei byte nel disco su cui sono fisicamente collocati i dati, è strettamente necessario costruirli con logica.
Spesso è importante considerare come i dati verranno utilizzati, ossia conoscere le varie query che dai da vari sistemi informativi, possono agire per interrogare il database.
Comunque si possono seguire regole generali per rendere più efficiente l’utilizzo del database, come limitarsi ad utilizzare le chiavi delle tabelle come indici, al limite utilizzare colonne che consentono un ordinamento logico dei dati.
TIPI DI INDICI: cluster e non cluster
CLUSTER:
Gli indici cluster ordinano e archiviano le righe di dati della tabella in base ai valori di chiave, ovvero alle colonne incluse nella definizione dell’indice. Per ogni tabella è disponibile un solo indice cluster, poiché alle righe di dati è possibile applicare un solo tipo di ordinamento.
Le righe di dati di una tabella vengono archiviate con ordinamento solo se la tabella contiene un indice cluster. Se la tabella non contiene un indice cluster, le righe di dati vengono archiviate in una struttura non ordinata denominata heap.
NON CLUSTER:
Gli indici non cluster presentano una struttura distinta dalle righe di dati. Un indice non cluster contiene i valori di chiave dell’indice non cluster, ciascuno dei quali dispone di un puntatore alla riga di dati che contiene il valore di chiave.
Il puntatore da una riga di indice non cluster a una riga di dati è denominato indicatore di posizione delle righe. La struttura dell’indicatore di posizione delle righe dipende dal tipo di archiviazione delle pagine di dati (heap o tabella cluster). Nel caso di un heap, l’indicatore di posizione delle righe è un puntatore alla riga. Nel caso di una tabella cluster, l’indicatore di posizione delle righe è la chiave di indice cluster.
QUANDO UTILIZZARE INDICI NON CLUSTER
Utilizzare un indice non cluster per le query con gli attributi seguenti:
- Query che utilizzano comandi JOIN o GROUP BY. Creare più indici non cluster in colonne interessate da operazioni di join e raggruppamento e un indice cluster in ogni colonna chiave esterna.
- Query che contengono colonne interessate di frequente da condizioni di ricerca di una query, ad esempio la clausola WHERE, che restituiscono corrispondenze esatte.
NOZIONI FONDAMENTALI SULLA PROGETTAZIONE DI INDICI
La selezione degli indici adatti a un database e al relativo carico di lavoro è un’operazione complessa che comporta la ricerca di un equilibrio tra velocità delle query e costi di aggiornamento.
Gli indici estesi, d’altra parte, coprono più query. Potrebbe essere necessario sperimentare diverse soluzioni prima di trovare l’indice più efficiente.
È possibile aggiungere, modificare ed eliminare indici senza modificare lo schema del database o la struttura dell’applicazione.
È pertanto opportuno sperimentare il funzionamento di vari tipi di indice.
Quando si progetta un indice è consigliabile attenersi alle linee guida seguenti sulle query:
- Creare indici non cluster nelle colonne che vengono utilizzate spesso in condizioni di join nelle query. È bene non aggiungere colonne non necessarie. Un numero eccessivo di colonne di indice può avere effetti negativi sullo spazio su disco e sulle prestazioni per la gestione degli indici.
- Gli indici di copertura possono migliorare le prestazioni delle query, perché tutti i dati necessari per soddisfare i requisiti della query esistono all’interno dell’indice stesso.
- Scrivere query che inseriscono o modificano il numero più alto possibile di righe con una sola istruzione, anziché utilizzare più query per aggiornare le stesse righe. L’utilizzo di una sola istruzione consente di avvalersi della gestione ottimizzata degli indici.
- Utilizzare molti indici per migliorare le prestazioni delle query nelle tabelle che vengono aggiornate raramente ma che contengono grandi volumi di dati. Un numero elevato di indici può contribuire a migliorare le prestazioni delle query che non modificano i dati, ad esempio delle istruzioni SELECT.
CONSIDERAZIONI
Un numero elevato di indici in una tabella ha ripercussioni sulle prestazioni delle istruzioni INSERT, UPDATE, DELETE e MERGE perché, quando vengono modificati i dati nella tabella, tutti gli indici devono essere modificati di conseguenza.
Ad esempio, se una colonna viene utilizzata in molti indici e si esegue un’istruzione UPDATE tramite cui i dati della colonna vengono modificati, ogni indice contenente la colonna in questione deve essere aggiornato.
MANUTENZIONE DEGLI INDICI IN SQL SERVER
Gli indici sono in genere aggiornati automaticamente ad operazione di modifica, inserimento o eliminazione dei dati.
Con il tempo gli indici perdono il loro ordine, ossia risultano essere deframmentati. Ciò può essere causa di un peggioramento delle prestazioni della tabella del database e di conseguenza delle performances delle applicazioni che lo utilizzano.
Nella fase di manutenzione del database è possibile quindi ridurre tale inconveniente, tramite due possibili operazioni:
riorganizzazione di un indice: è un’operazione di riordino dell’indice corrente, che non impedisce l’utilizzo del database consumando una quantità minima di risorse;
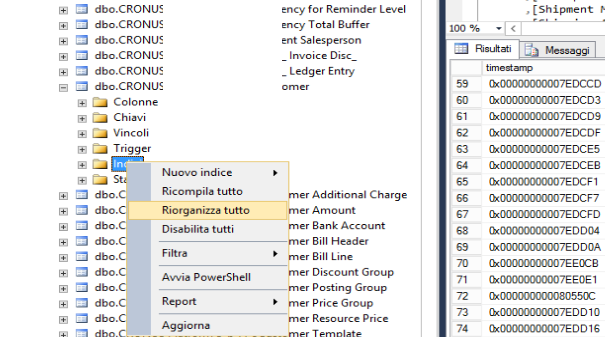
ricompilazione di un indice: è un’operazione che elimina e ricrea nuovamente l’indice, durante tale operazione la tabella risulta inaccessibile.
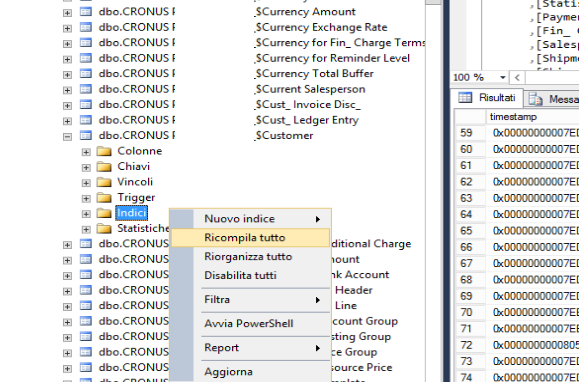
Gli indici possono essere manipolati tramite codice utilizzando il comando ALTER INDEX, per fare questo l’utente deve possedere almeno il ruolo minimo nel database db_ddIadmin , per questa operazione si rimanda per il dettaglio alla numerosa documentazione on line sulle funzioni di MICROSOFT SQL SERVER.
Tramite semplice interfaccia grafica di SQL Server Management Studio, le operazioni di creazione e manutenzione possono avvenire in maniera immediata.
Nelle proprietà degli indici ci sono diversi parametri che possono essere presi come indici dello stato di salute del database, come, tra le più utili:
- Livello di riempimento pagina: indica quanto sono piene le pagine;
- Frammentazione Totale: numero delle pagine di un indice che non sono archiviate in ordine;
In genere, quando la frammentazione è compresa tra il 10-30% è utile riorganizzare l’indice, altrimenti se superiore, si consiglia la ricompilazione (tenendo presente che questa operazione rende offline le tabelle interessate).
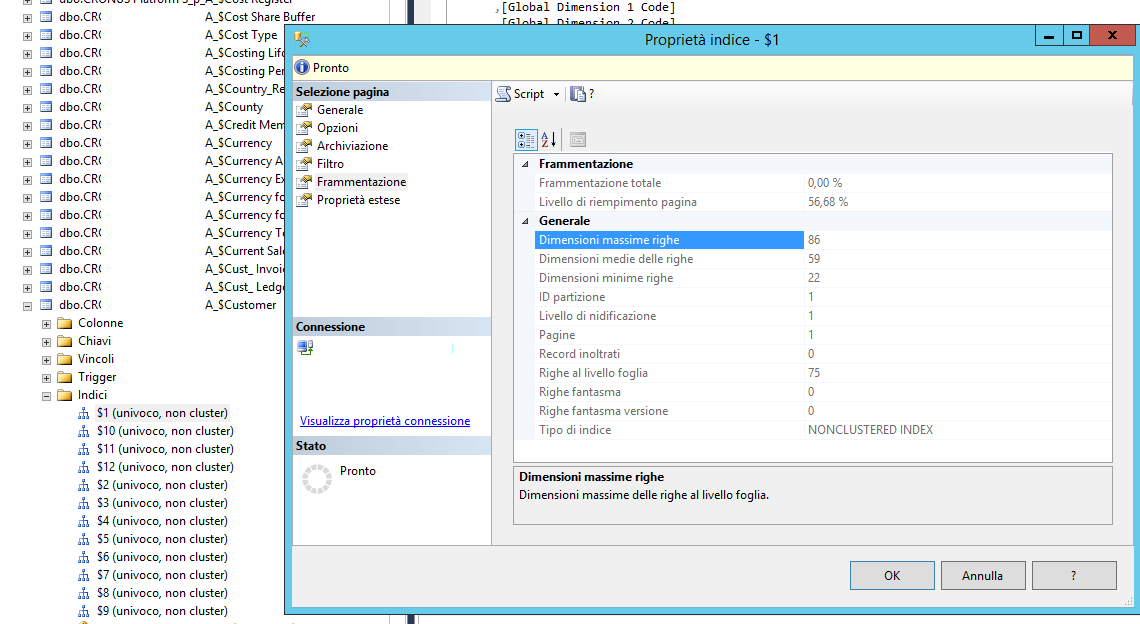
Schermata delle proprietà dell’indice, scheda Frammentazione, in SQL Server Management Studio
Per approfondimenti sul tema, si rimanda alla documentazione on line di Microsoft SQL Server:


0 Comments